Post-Hoc Reasoning in Chain of Thought
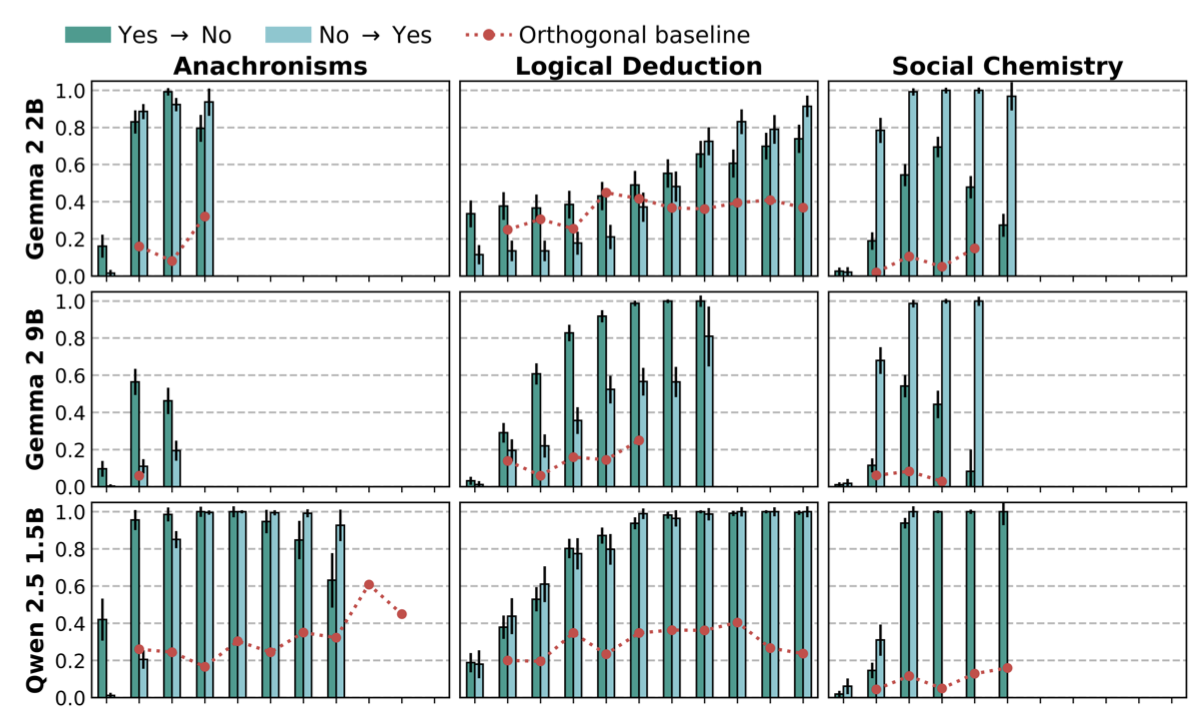
I started this project during the training phase of Neel Nanda's MATS 6.0 stream. Later, with the help of some collaborators (Darius Kianersi and Adrià Garriga-Alonso), I extended it with a more comprehensive evaluation suite and some additional experiments. Over time this has resulted in three different artifacts for the same project: a blog post on this site, a LessWrong post, and a paper. I had GPT 5.5 Deep Research aggregate citations across the three artifacts, which I list below.
In the future, if you reference this project, I recommend you cite the paper on arXiv! I've provided a BibTeX citation at the bottom of the page.
Cited by
as of June 2026Papers
- LLMs Faithfully and Iteratively Compute Answers During CoT: A Systematic Analysis with Multi-step Arithmetics cites LessWrong post
- Do Thinking Tokens Help with Safety? cites paper
- What’s the plan? Metrics for implicit planning in LLMs cites blog post
- Chain-of-Thought Reasoning in the Wild Is Not Always Faithful cites LessWrong post
- Scaling Latent Reasoning via Looped Language Models cites blog post
- The Detection–Extraction Gap: Models Know the Answer Before They Can Say It cites paper
- Measuring and Mitigating Post-hoc Rationalization in Reverse Chain-of-Thought Generation cites LessWrong post
Other
- CoT May Be Highly Informative Despite “Unfaithfulness” cites LessWrong post
- Understanding Reasoning with Thought Anchors and Probes cites paper
- The Innocent-Suspect: Alignment, Awareness, and the Case for Trust cites paper
Cite this project
@misc{cox2026decodinganswerschainofthoughtevidence,
title = {Decoding Answers Before Chain-of-Thought: Evidence from Pre-CoT Probes and Activation Steering},
author = {Kyle Cox and Darius Kianersi and Adrià Garriga-Alonso},
year = {2026},
eprint = {2603.01437},
archivePrefix = {arXiv},
primaryClass = {cs.AI},
url = {https://arxiv.org/abs/2603.01437},
}